LoLTracker
L'approche de Riot contre les tricheurs

Les articles du blog d'ingénieurs de Riot sont souvent très intéressants. En revanche, ils sont très longs, et souvent très techniques, donc difficiles et longs à traduire en conséquence. Toutefois, le sujet du jour est intéressant pour tous les joueurs, et pas juste ceux intéressés par l'approche technique. Il s'agit du combat contre les tricheurs. Une chose face à laquelle Riot a une approche bien particulière...
L'approche de Riot contre les tricheurs
Combattre la triche est sans fin. L'étendue et la complexité du développement de la triche grandissent chaque année avec les enjeux dans les jeux en ligne. La pression est sur les développeurs de jeu pour s'améliorer dès lors qu'il s'agit de détecter et d'empêcher les mauvais acteurs d'agir. Je suis Michael "perma" VanKuipers, et je fus l'un de ces mauvais acteurs. J'ai passé plus de 10 ans à développer des cheats pour divers jeux, et suscité la colère d'au moins un grand studio dans ce procédé. Aujourd'hui, je travaille sur le programme anti-cheat de Riot, et aide à sécuriser le jeu contre les scripts, les bots, et divers exploits. Dans cet article, je vais vous montrer comment certains des détails et stratégies derrière notre dernière initiative anti-cheat, incluant une perspective des étapes techniques que nous avons franchies pour mitiger certains types de cheats.
Note : Nous avons travaillé avec beaucoup de créateurs et de vendeurs de logiciels tiers pour nous assurer que leur outil continuera à être compatible avec le jeu. Si vous avez toujours des erreurs ou des inquiétudes concernant la légitimité de vos logiciels tiers, consultez les problèmes connus et leurs correctifs, ou contactez le support pour une assistance individuelle.
Avant de commencer, je devrais commencer l'article par ça : Parler des anti-cheats est compliqué. Il faut jongler avec la conversation ouverte et honnête et la protection du secret. Il y a certaines choses qu'il n'est pas possible de partager pour le bien des joueurs et l'intégrité du jeu. Cela dit, nous ne pensons pas que l'efficacité dépend uniquement du secret, et nous avons beaucoup travaillé sur le développement de solutions techniques pour ces problèmes. Avec cet article, j'espère vous donner une bonne compréhension du type de menaces que nous voyons dans le domaine de la triche, et de comment nous changeons le jeu pour les réduire.
Notre philosophie contre la triche
Lorsqu'il s'agit de garder nos produits équitables, mon équipe se focalise principalement sur 3 aspects : La prévention, la détection, et la dissuasion

Pendant plusieurs années, la détection et la dissuasion étaient les stratégies de la plupart des studios de jeux vidéo. En général, la plupart des techniques amènent à laisser le tricheur jouer quelques parties, détecter son comportement anormal (Soit en surveillant les changements fait au jeu, ou en analysant leur pattern dans le jeu), et ensuite, les exclure de la population de joueurs.
Aujourd'hui, cette approche est toujours la plus commune qu'on peut voir. Elle a du sens, mais elle signifie que la barrière à franchir au départ pour créer des cheats n'est pas très élevée. Par ailleurs, les joueurs subissent les tricheurs dans leurs parties le temps que le système les détecte. Cela fonctionne, mais ce n'est pas idéal.
Une solution plus efficace est d'empêcher la triche de se produire. Si nous réussissons, nos joueurs n'auront pas à avoir des bots ou des scripters dans leur partie. La détection et les exclusions sont toujours importantes, mais nous serons moins amenés à l'utiliser. C'est un bon objectif, et c'est ce qui nous a conduits aux changements effectués à notre technologie et à notre stratégie.
Les types de cheats
Il y a certains comportements que nous n'encourageons pas dans League of Legends parce que nous ne voulons jamais que nos joueurs questionnent l'intégrité du jeu. Nous classons ces comportements comme de la triche parce qu'ils détruisent l'expérience compétitive qui fait que nous aimons le jeu. Notre solution se focalisera principalement sur le cheat "technique", celui qui nécessite l'utilisation d'un logiciel tiers qui interagit avec le jeu. Cette catégorie de mauvais comportement peut être divisée en deux principales sous-catégories : Les bots, et les scripts. Ils peuvent être combinés et implantés de manières très créatives. Nous allons explorer certains cas plus tard dans l'article.
Le script
La première de ces sous-catégories est le script, où un programme tiers s'attache de force au client de jeu, et utilise sa mémoire et ses fonctionnalités pour accomplir ce qui serait en tant normal difficile ou impossible. Par exemple, on trouve parmi les techniques communes l'aide aux joueurs pour éviter les skillshots, un zoom arrière plus grand que ce qui est normalement possible, pour l'exécution parfaite de certains combos pour battre l'adversaire.
Ces scripts peuvent aller de choses très simples (Comme le hack du zoom), à des choses très complexes avec des nuances pour chaque champion (Comme donner à Kalista des techniques de manœuvres supplémentaires). Malgré le degré de sophistication de certains des scripts que nous voyons dans League of Legends, la plupart des scripters ne voient qu'une augmentation symbolique de leur taux de victoire.
Sur l'image ci-dessous, vous pouvez voir l'interface typique d'un scripter, qui indique la portée de plusieurs compétences, indique quels sbires sont prêts à être tués, et montrent le chemin des projectiles des skillshots.
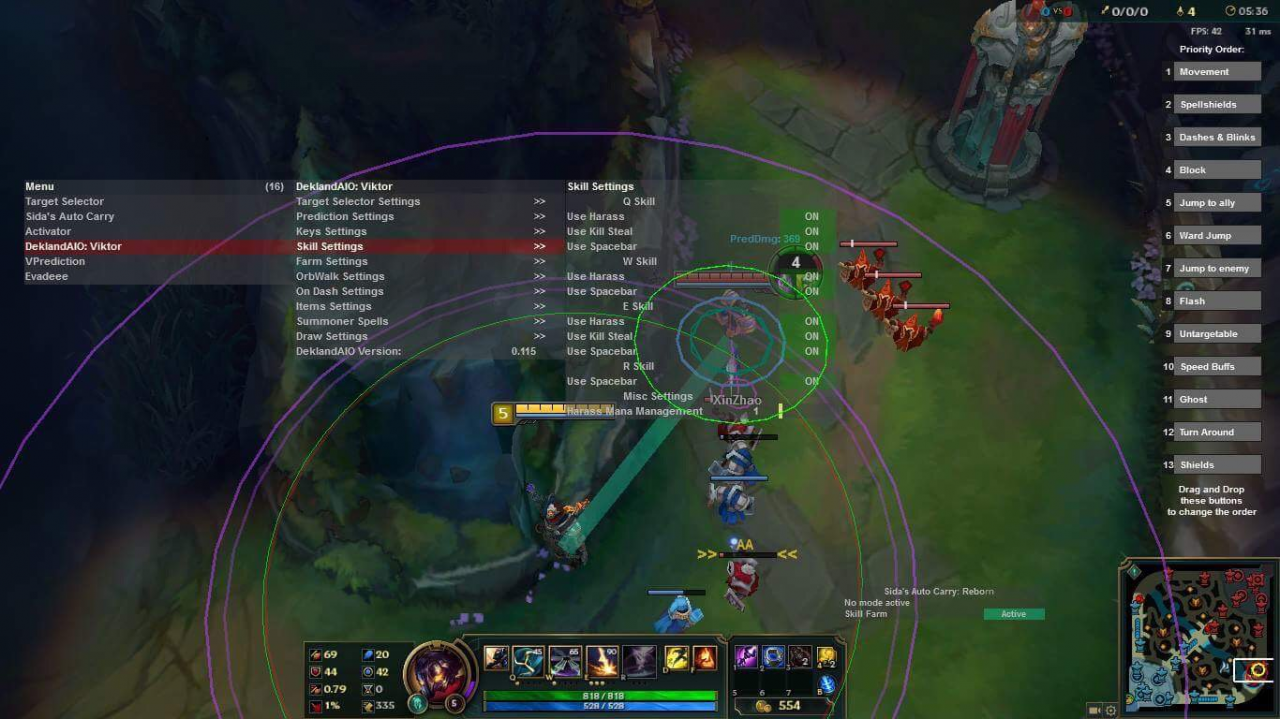
Les bots
La deuxième sous-catégorie que nous voyons communément est le bot. La plupart du temps, il s'agit d'un logiciel tiers simulant des déplacements sur lane pour mourir à la fin, ou des semblants de gameplay pour déguiser le fait qu'il s'agit d'un bot. Ils sont utilisés principalement pour monter des comptes et les vendre ensuite, ou pour farmer les essences bleues.
La démarche pour mitiger le phénomène
Avec comme objectif de rendre le cheat difficile en premier lieu, nous avons commencé avec le client de jeu. La pièce la plus vulnérable de chaque jeu est le client, dans la mesure où il se trouve dans la machine du tricheur, où ils ont un contrôle total sur le logiciel lancé, et les permissions pour le jeu. Avec ça en tête, nous voulions rendre le client de jeu aussi difficile que possible à analyser et à exploiter.
Une part de cette démarche vient avec une bonne conception du jeu. Nous avons eu de la chance avec l'état actuel de League of Legends parce que beaucoup de décisions de bonne conception avaient déjà été prises :
- Nous ne partageons pas l'état des autres joueurs si ce n'est pas nécessaire, ce qui permet d'éviter des cheats comme des "map hacks", qui révèlent tous les joueurs sur la map.
- Nous laissons le serveur de jeu avoir l'autorité sur les décisions du jeu, et ne faisons généralement pas confiance aux informations reçues via le client du jeu, ce qui aide à éviter des cheats communs, comme les "god mode", et les "disconnect hacks".
- Notre protocole réseau a été obscurci, et nous le modifions régulièrement, ce qui rend beaucoup plus difficile la conception d'un bot basé sur les données envoyées au serveur.
Maintenant que vous avez une idée des défis auxquels nous faisons face, jetons un œil à certaines de manières que nous utilisons pour combattre les cheats communs. J'ai pris 3 exemples spécifiques de techniques que nous avons mis en place pour répondre aux techniques que les développeurs de cheats utilisent traditionnellement pour attaque le client de jeu. Dans chaque section, je discuterai comment les cheaters font pour compromettre le jeu, et comment nos efforts anti-cheat ont ralenti leurs progrès.
Encrypter le code du jeu
Un des aspects du client de jeu qui le rendait vulnérable jusqu'à présent était le code du jeu lui-même. Les développeurs de cheats ont été historiquement capable d'analyser l'exécutable du jeu en utilisant leurs débuggers/désassembleurs, et ont trouvé les fonctions qu'ils voulaient utiliser. À partir de là, ils peuvent "prendre" ces fonctions importantes pour obtenir des informations sur l'état actuel du jeu.
Il s'agit d'une technique très commune dans le développement de cheats qui implique la redirection de la logique en jeu vers un code personnalisé. Cela permet à l'application de cheat d'effectuer des actions spéciales pendant ces routines. Par exemple, si un cheater prends la fonction où les effets visuels sont dessinés, ils peuvent utiliser leur localisation et leur direction pour déterminer où va la compétence, et s'ils doivent déplacer le joueur en dehors d'un skillshot.
En général, ce type de récupération est fait par l'application qui injecte du code dans le client de jeu. Une méthode populaire pour charger ce code personnalisé dans Windows implique d'injecter un fichier DLL dans le jeu. La DLL peut alors demander un saut ou appeler une instruction dans la fonction de ciblage du jeu, changeant le flux du programme par le code contenu dans la DLL. Une fois ce code terminé, l'application de cheat passe le relais au code du jeu. Voici une illustration de ce processus :

En plus d'appeler leur propre code en fonction de ce qu'il se passe en jeu, une DLL permet aux tricheurs d'appeler le code du jeu pour effectuer des actions comme des attaques ou des déplacements du champion. Cela permet un développement relativement facile des scripts et des bots une fois que le cheater comprends le code du jeu. Même un (relativement) nouveau développeur de cheats peut utiliser un outil de recherche dans la mémoire et commencer à apprendre où sont les divers éléments du jeu et comment les manipuler. Ces changements dans la mémoire sont détectés avec le client de jeu, mais Riot voulait prévenir en premier lieu ce type de comportement.
Avec cet objectif en tête, nous avons rendu le piratage du client de jeu plus difficile en cryptant le code du jeu. Il y a des applications commerciales disponibles connues sous le nom de "packers" qui font déjà ça, mais nous voulions utiliser une solution maison, qui nous donnerait plus de contrôle sur les performances et la qualité. Cette solution nous aussi la possibilité d'intégrer des mesures de sécurité davantage liées au jeu, ce qui rend la protection plus facile à adapter au jeu, tout la rendant plus complexe à décrypter pour les tricheurs.
Pour pouvoir encrypter le code du jeu, nous avions besoin de simplifier des parties de l'exécutable du jeu qui contenaient le code. Comprendre comment nous avons accompli cela nécessite une idée générale sur comment le format de fichier d'exécutable portable (PE) fonctionne sur Windows. Il s'agit d'un format qui est ce que le système utilise pour charger et exécuter les fichiers avec un code à lancer. Cela inclut les fichiers communs, comme les .exe et les .dll, les drivers systèmes, etc... Chaque fichier PE est divisé en un certain nombre de sections. Chaque section du fichier dispose d'un "Section header" qui fournit les détails pertinent sur la section, comme son nom, sa taille, et sa position dans le fichier. Voici une illustration de cette structure :

Du fait que notre solution se focalise sur l'encryptage de portions de code du client de jeu, nous avons sélectionné la section .text dans le fichier, qui est l'endroit où le code exécutable d'un programme est émis par un compilateur par défaut. Les packers traditionnels procèdent à leur encryptage en créant un utilitaire d'amorçage qui prend le binaire original du jeu, trouve les sections pertinentes qui ont besoin d'être encryptées en examinent les sections headers du fichier PE, puis applique un encryptage via un algorithme à ces sections. Nous avons aussi utilisé cette approche, en nous focalisant sur la section .text.

Une fois cette section dans le binaire encrypté, nous avions besoin de la décrypter lorsqu'elle était exécutée. Si quelqu'un voulait lancer le client de jeu tel quel, il crasherait, parce que le point d'entrée de l'application serait un paquet de lignes cryptées. Beaucoup de packers gère ce point en injectant leur propre code pour décrypter le code dans l'exécutable et écraser les adresses des points d'entrées dans le fichier PE, de sorte à ce qu'il renvoie à leur code de décryptage. Cela a pour effet de faire exécuter le code de décryptage en premier lorsque le programme est lancé. Une fois le décryptage de la section .text effectué, il peut renvoyer l'exécution au point d'entrée original, et le programme fonctionne alors normalement.
Malheureusement, cette technique avait des limitations que nous voulions surpasser. En travaillant sur cette solution, nous nous sommes rendu compte qu'il serait avantageux si nous pouvions valider certaines des dépendances du jeu avant que cela ne soit nécessaire. Cela nous permettrait de faire des vérifications pour voir si des changements inhabituels ont été faits sur les librairies utilisées par le jeu.
Nous ne serions pas en mesure de mettre en place ce niveau de validation en utilisant la technique classique que nous avons vu juste avant. Le système d'exploitation chargerait nos dépendances avant l'appel du point d'entrée du programme, et avant l'autorisation du lancement du décryptage du code. Cela signifierait que n'importe quelle librairie qui aurait été altérée serait déjà chargée, et nous ne pourrions pas vérifier de manière fiable leur intégrité. Nous savions qu'il nous fallait une meilleure approche.
Nous avons découvert que nous pouvions utiliser la manière dont le système d'exploitation chargeait les dépendances pour les fichiers PE à notre avantage. Lorsqu'une application est compilée, l'import de descripteurs est généré, et inséré dans l'exécutable pour n'importe quelle librairie externe qui est référencée par le programme. À partir de là, chaque fonction spécifique importée ou variable est listée comme une part du descripteur importé. De cette manière, le système d'exploitation peut savoir quelles DLLs doivent être chargées pour que le programme fonctionne correctement. Ces imports sont stockés comme des chaînes de caractères pendant la compilation dans un tableau appelé "Import Name Table" (INT), qui est référencée par ce descripteur importé de la librairie. Lorsque le programme est chargé, le système d'exploitation résout les localisations des imports référencés dans le INT, et remplit "l'Import Address Table" (IAT) avec l'adresse actuelle de ces imports. Vous pouvez voir ce processus ci-dessous :

Que se passerait-il si nous générions une librairie externe qui procédait au décryptage au lieu de l'inclure dans le jeu lui-même ? En utilisant cette approche, nous nous assurons que notre librairie de décryptage est la seule chargée en modifiant les descripteurs importés du jeu pour ne lister que notre librairie. En conséquence, nous l'avons chargée en premier, et nous avons l'opportunité de valider les autres dépendances. Cela ne se fait pas sans inconvénients cependant. Cela signifie aussi que nous devons gérer et charger les autres dépendances nous-mêmes. Le jeu a beaucoup d'imports, et depuis que nous les avons tous remplacés par notre module d'amorçage, nous devions nous assurer que nous gardions une trace de ce qui avait précédemment besoin d'être importé. Nous avions ensuite à charger ces librairies externes nous-même pendant l'initialisation, et à remplir l'IAT du jeu pour chacune de ces librairies, puisque le système d'exploitation ne pouvait plus le faire pour nous. Dans ce cas de figure, nous étions prêts à renoncer à la commodité d'avoir le système d'exploitation qui chargeait nos imports, en échange d'avoir la capacité de les valider avant qu'ils ne soient chargés. Nous pensons que ça valait le coup.
À ce moment, nous avions accompli notre but de rendre l'analyste statique plus difficile. Si quelqu'un ouvrait le jeu dans un désassembleur, il serait accueilli par un paquet de code incompréhensible. Qui plus est, nous nous sommes assurés que seules des portions du code du jeu sont décryptées pendant le jeu, plutôt que de toutes les décrypters en une fois. Cela aide à nous protéger contre une section .text entièrement décryptée dans la mémoire après son chargement.
Le problème suivant à gérer était l'analyse dynamique. Qu'est-ce qui se passe après que le jeu a été chargé et qu'une part de ce dernier a été décryptée ? À ce moment dans notre processus, le code du jeu pouvait être facilement analysé par un débuggeer. Cela aurait rendu nos efforts beaucoup moins efficaces.
Rendre la vie difficile aux débuggers
Comme alternative à l'analyse statique du jeu, un créateur de cheats va souvent attacher un débugger au client de jeu pendant qu'il est exécuté. Faire ceci leur permet d'examiner le code pendant son déroulement, et de déterminer comment il fonctionne. Il y a beaucoup de recherches en ligne sur les techniques d'anti-debuggging, qui peuvent rendre les choses très difficiles pour quelqu'un essayant de débugger un exécutable en cours de fonctionnement. Nous avons senti qu'il était prudent de les inclure, avec autant de variations qu'il était raisonnablement possible d'envisager.
Le jeu et l'amorceur sont deux zones que nous voulions protéger, et idéalement nous pouvions le faire d'une manière qui rendait les analyses automatisée difficiles. Pendant l'amorçage, nous insérons une vérification aléatoire pour détecter la présence d'un debugger à travers le code, et nous rendons aléatoire la vérification qui apparaît à chaque build. Au moment de la compilation, une vérification anti-debug aléatoire est insérée à chaque endroit où cela est demandé dans le code. Dans certains cas, la vérification n'est pas demandée, ce qui fait que certains endroits dans le code sembleront ne pas avoir de vérifications dans un build, mais en aurons une dans un autre build. Cela change d'un build à l'autre, comme le code lui-même pour beaucoup des vérifications.
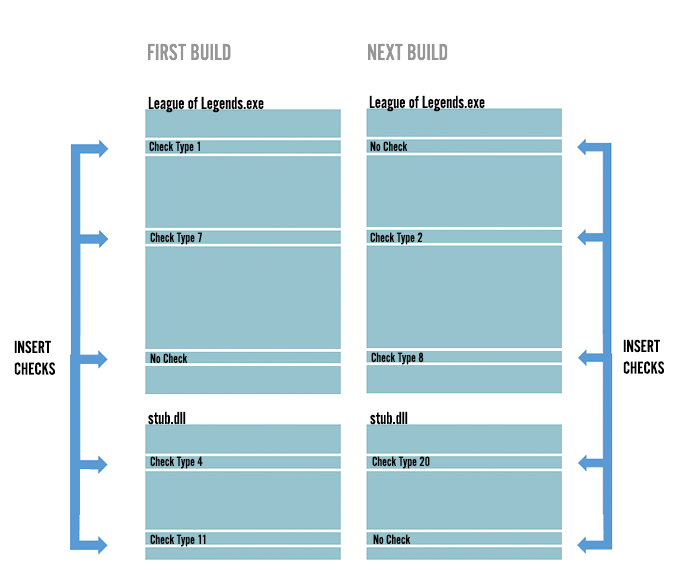
Pour augmenter la complexité de l'analyse, différentes vérifications produisent différents résultats. Par exemple, pendant une vérification, nous pouvons signaler qu'un debugger a été détecté, et pour une autre vérification, nous pouvons changer le comportement du code après la vérification, ou provoquer un crash du jeu 5min plus tard. Cette imprévisibilité aide à garder la détection plus difficile à constater, et nous aide également à avoir des données sur le moment et la manière dont les auteurs de cheats essayent d'analyser le client de jeu.
Protéger nos données
Une fois que le code de notre jeu était protégé et que nous avions confiance dans nos mesure anti-debug, il y avait un dernier vecteur d'attaque commun où nous pensions que nous pouvions procéder à des améliorations pour rendre plus difficile son exploitation. Alors que tout notre code était maintenant protégé, les membres de classes et les variables globales, dont les valeurs et les pointeurs étaient dans la section .data du fichier PE, et la zone mémoire pré-réservée (Heap) ne l'étaient pas.
Beaucoup de développeurs de scripts et de bot utilisent des outils de recherche en mémoire pour trouver des données dans le jeu, comme les PV, le mana, etc... Et utilisent ensuite les emplacements mémoire pour trouver d'autres détails. Par exemple, les PV et le mana peuvent être un élément d'une classe ou d'une structure qui représente le joueur, et cette structure peut contenir d'autres informations comme la position du joueur, le niveau, la direction dans laquelle ils vont, etc... Ce type d'informations est particulièrement utile pour les scripts qui essayent d'automatiser des comportement comme l'évitement des skillshots.
Les outils de recherche en mémoire fonctionnent en passant à travers les zones de mémoire du jeu, et en cherchant des valeurs spécifiques à l'utilisateur. Par exemple, une valeur de PV à 100. L'utilisateur va alors subir des dégâts, et voir ses PV tomber à 90, et ensuite l'outil de recherche va tenter de trouver les valeurs qui valaient 100 auparavant et sont tombées à 90.
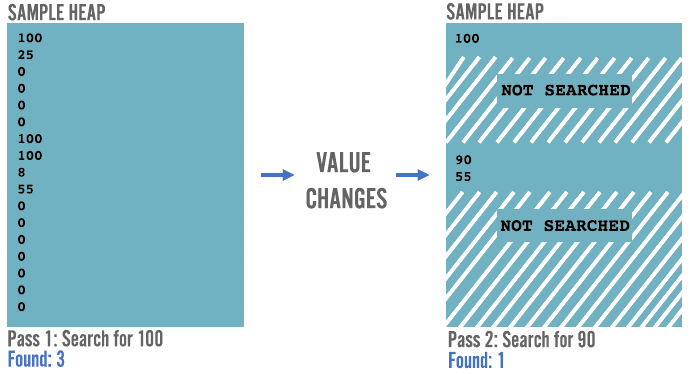
Ils continuent cette opération encore et encore, jusqu'à ce que leur recherche n'ait plus que quelques adresses mémoires dans leurs résultats, et ils peuvent alors trouver laquelle correspond aux PV avec des tests.
Nous bloquons cette technique commune en nous assurant que lorsque la valeur est modifiée parce que le joueur subit des dégâts, elle change également d'adresse mémoire. Cela signifie que nous n'allons pas écrire ce 90 au même endroit que là où était écrit le 100.

Cela pourrait déjà causer des problèmes à la plupart des outils de recherche en mémoire. Idéalement, les valeurs de 100 et 90 devrait ne jamais être stockées en premier lieu. Cela forcerait les développeurs de cheats à chercher uniquement les valeurs ayant été modifiées, plutôt que de spécifier une valeur exacte, ce qui rend le procédé bien plus difficile. Pour en arriver à ce niveau, nous avons ajouté un encryptage aux données, ce qui fait que les valeurs originales ne peuvent pas être trouvées dans cette zone mémoire. Et pour compliquer encore plus la tâche des développeurs de cheats, nous avons aussi fait en sorte que chaque valeur utilise un encryptage légèrement différent.
Nous sommes maintenant capables de répandre ces valeurs protégées librement dans le code du jeu, dans les zones où nous pensons qu'elles sont les plus importantes. Nous avons déterminé leur priorité en analysant les cheats existant, et en observant les données qu'ils utilisent.
Assembler le tout
Pour l'an prochain, nous restons engagés dans nos efforts pour protéger le jeu, et nous savons qu'il y aura de nouveaux obstacles. Nous nous attendons à ce que le combat contre les cheats continue à être une escalade d'armes, mais nous voyons l'encryptage, l'anti-debug, et la protection des données vues dans cet article comme un grand pas en avant pour améliorer l'expérience des joueurs dans le monde.
Pour être franc, ce n'est qu'une fraction des efforts et des fonctionnalités que nous avons mis en place dans notre dernière solution anti-cheat. Nous avons signalé qu'il y avait des éléments dont nous ne pouvions pas parler, et nous en avons exclus beaucoup. Après tout, nous avons besoin de garder certaines choses secrètes pour combattre l'intelligence artificielle dans le futur. Ceci dit, j'espère qu'en parlant de manière plus ouverte de nos solutions de sécurité, nous pouvons poser les bases d'une discussion technique plus ouverte pour le futur.
Envie de faire partie de notre combat contre les cheaters ? On recrute !
À propos de l'auteur
Loading comment...
The comment will be refreshed after 00:00.
Be the first to comment.
Derniers articles
LoLTracker ferme ses portes après plus de 10 ans de bons et loyaux services !
Thèmes abordés : Fermeture imminente du site, Project L, pause de fin d'année chez Riot, Riot mobile, et bien plus !...

Analysons les problèmes actuels de Yuumi et notre manière d'aborder sa refonte.

Une nouvelle mise à jour a eu lieu sur le PBE, apportant de l'équilibrage

C'est le dernier patch de l'année, la 12.23B est là !